An alarm clock for werewolves

Made with: Braun BC02BL travel alarm clock, Gepetto Electronics lavet motor clock movement controller board with lunar clock firmware, custom designed replacement clock face.
The original controller board was an integral part of the clock movement, so I left it in place, but cut the power to it and rerouted it to the replacement board, which I crammed into a small bit of empty space inside the case. The minute hand has been removed, and the “hour” hand now goes around every 29.530 days (which makes it really annoying to tell if the battery is dead, since it only ticks one “second” in every ~59).
This has no practical purpose for me, but it was a fun exercise in graphic design (plus a bit of soldering practice), and it makes a neat-looking conversation piece.
Literate programming, unTANGLEd
When the topic of literate programming comes up, there’s a tendency to bemoan a lost art. A lot of people complain that, while Knuth’s WEB system allowed the user to write their code in whatever order made sense for the narrative, modern so-called “literate programming” tools more or less just extract all the code blocks from a markdown file, constraining the presentation format to whatever order the computer demands. What this analysis misses, I think, is that this is much less of a constraint with modern programming languages.
Hints for diagnosing memory leaks in NodeJS
A couple of things I keep having to rediscover when diagnosing crashes in Node programs caused by running out of memory:
- Set
--max-old-space-size=100(or some other smallish number of megabytes) to make the crash happen faster and reduce the chance of it bringing down other things on the system. - Set
--heapsnapshot-near-heap-limit=1to generate a*.heapsnapshotfile when the runtime thinks it’s close to running out of memory. This process takes a long time and a lot of memory of its own (seemingly roughly twice the heap size, more or less), so settingmax-old-space-sizeto something relatively small seems mandatory when using this option, to avoid the snapshot process itself running out of memory. - The resulting profile can be loaded in the Chrome developer tools’ Memory tab for viewing.
A tiny plaintext accounting tool
I have been doing some financial planning, and needed to make sure I hadn’t gotten mixed up when trying to keep track of how much money will be where at some point in the future as I shuffle it around between accounts. The spreadsheet I tried to build got unwieldy quickly and I decided I needed a special-purpose tool. I’ve heard of hledger and beancount, and briefly tried them out a few years ago, but they do way more than I needed for this task and I wanted to avoid getting distracted by learning a new tool. So in the end I coded up a special-purpose tool to help, and it seemed interesting enough that I decided to write about it here.
Eventual consistency in package tracking numbers
(This post is a mirror of a Hacker News comment I wrote.)
The "invalid tracking number" thing drives me nuts. Both Fedex and UPS do it. How hard is it to stick a record in the database the moment a tracking number is generated so that I don't get a "This tracking number is invalid" message? And it's not like it's invalid for a few minutes; I've had tracking numbers remain "invalid" for almost a day. Absolutely insane.
A lot of the systems involved were designed in an era before ubiquitous connectivity, when electronic data transfer involved calling a mainframe over the phone with a modem or sometimes even mailing magnetic tape. In that world the answer to “how hard is it to stick a record in the database” is “surprisingly complicated,” so these systems tend to work on the principle of “very eventual consistency.” I used to work for a company that had been doing eCommerce since the early 2000s, so can give an example of the way this happened:
A bit of DOM sugar
I’ve been carrying this snippet around in my head for years, embedding it in projects where I just need a tiny bit of JS:
function $e(t,p,c) {
const e=document.createElement(t)
Object.assign(e,p)
e.append(...c)
return e
}
Usage:
const button = $e('button', {onclick: () => alert('click!')}, [
$e('img', {src: '/assets/icon-lightbulb.png'}, []),
'Ding!',
])
Judging from the comments when I’ve posted this, it seems to have been independently invented by a lot of different people, frequently down to calling it $e. It also matches the signature of jsxFactory, so can be used with a React-compatible transpiler; for example TypeScript can be configured with {"jsxFactory": "$e"}.
Ambiguity in natural language interfaces for programming
There’s been a lot of discussion recently about whether conversational AI will replace programmers any time soon. One of the arguments against this happening is that natural language is inherently ambiguous; you need to very precisely specify what you want, and that looks like... a programming language, with all of the inherent complexity that programmers are there to manage. I think this rather misses the point: programmers also provide a natural language interface to their users, and somehow usually manage the ambiguity and complexity OK.
(This post is a lightly edited version of a Hacker News discussion).
The Teletype dance
(Mirror of a Hacker News comment I wrote, responding to someone who wondered what a serial connection actually looked like “on the wire.”)
I binged CuriousMarc’s YouTube series on teletype restoration a few months ago, so here’s a simplified (and possibly somewhat inaccurate) explanation of how one works.
The only electrical components in a Teletype are (a) a continuously-running electric motor, and (b) an electromagnet and a few switches. Everything else is completely mechanical.
The Teletypes in a circuit, and the electromagnet and switches within them, are all connected in series, forming a current loop. (Current, rather than voltage, is used because you can use a constant-current power supply to get the same power at each electromagnet regardless of how many are in the circuit and how many miles of wire are between them.)
Notes on <noscript>
My experience has been that <noscript> is too unreliable to be usable: the problem is that a lot of users browsing “with JavaScript turned off” are actually browsing with it turned on but not executing (some arbitrary subset of!) the <script> tags on the page.
The way to achieve the same effect without this problem is to include the nojs content unconditionally, and then have your script delete it from the DOM somewhere far enough through execution that you're confident that your script and its dependencies are all running properly. Otherwise you end up in situations where the JS is broken because something is being blocked, but it's working just well enough that the browser isn't showing the nice message you wrote explaining what the problem is.
(This post is a mirror of a Hacker News comment I wrote.)
Seeking on a UNIX pipe
taciscatspelled backwards it prints the contents in reverse order.How is input to a pipe reversed?
It’s written to a seekable tempfile first: github.com/coreutils/.../tac.c
(This post is a mirror of a Hacker News comment I wrote.)
The future of computing is here
What I want is a storageless-first serverless connectionless computerless apps.
I think you may have just invented the whiteboard.
(This post is a mirror of a Hacker News comment I wrote.)
The Triplebyte data download doesn’t give you all your data
In May of last year I decided to start looking for a new job, and started by taking Triplebyte’s quiz. Having passed that, I spent the next three months going through the rest of their process, from a two-hour remote interview all the way through to final negotiations with the company whose offer I selected. Throughout the process they were extremely competent and helpful, and at the end of it all I had only good things to say about them. They made the whole process go extremely smoothly, answered all the questions I had and gave me a ton of advice on the whole process, and their screening process was not only great from the my perspective but also gave me confidence in the quality of all their candidates.
“Scientists baffled”
It seems like scientists are always baffled. (What’s that old quote about “the most important phrase in science is ‘hmm, that’s funny...’”?)
Being baffled is pretty much a scientist’s job.
(This post is a mirror of a Hacker News comment I wrote.)
Parsing an SVG path command
(Mirror of a comment I wrote on a GitHub issue, responding to someone who was wondering how to parse the SVG path command a8 8 0 100-16 8 8 0 000 16, which looks at first glance like mangled data.)
This arc command is correct and standards-conformant SVG; see SVG 1.1 §8.3.9 for an exhaustive grammar, but the gist of it is that you can condense a lot.
On the removal of price caps for legacy domains
(A mirror of my public comment on ICANN's proposed renewal of the .org registry agreement, which included a widely-protested provision to remove the 10% limit on the price increases that the registry could charge for registrations and renewals.)
Like many others who have already submitted comments on this proposal, I have grave concerns about the provision to remove the price caps on registry fees for .info and .org top level domains. (I refrain from commenting on .biz as I do not own any such domains nor do I personally frequent websites using this TLD, but my concerns are applicable there also.) I say this not only as the owner of several domains (for whom these potential price increases have a direct monetary impact), but also more generally as a user of Web sites and Internet services. There is already growing social concern about the centralization of access to information with large corporations, who increasingly mediate the average person's experiences and interactions on the Internet. The Domain Name System provides a valuable part of the antidote to this problem: it allows individuals to set up their own corner of the Internet as they wish, largely unbeholden to anyone else; and allows anyone else to easily locate it on demand. This latter aspect is what makes pricing of domain names critical: because the domain name is the identifier used to locate a site or service, abandoning it breaks the ability for others to find it easily, and moving domain names requires rebuilding all links and trust from scratch, a long and tedious process which can never be fully completed. If a registry is allowed to raise fees in an arbitrary and unbounded manner, many of these registrants will decide that the expense is no longer worth it and abandon the registration--or even be forced to as the costs become unaffordable.
Coping with inherited code
(Mirror of a comment I wrote in response to the question “Have you ever inherited a codebase nobody on the team could understand? How did you deal with it?”)
I inherited a suite of .NET/WinForms applications that managed warehouse shipments to major purchasers. They had been written and modified by a succession of programmers with wildly different opinions of how to write a program (from copy-paste duplication to massively overarchitected inheritance trees; fully denormalized tables to 6th normal form; and everything in between). I was the only software developer at the company, so there was nobody else to ask how any of this worked; I had to figure it all out from scratch. The steps I took were:
RAAF Syko machine manual
The Syko machine was a British strip cipher used during WWII for encoding radio communications between aircraft. There's not much information on the Web about these machines; a scan of the Syko Manual (PDF, 2.4MB) is available but it's rather hard to read as it's an old document and has had extra annotations added.
In this post, I have transcribed the entire document to make it easier to read and find information about how the Syko machines were operated.
Working offline
How would you work offline on a bus ( or plane, or train )? [...]
Which tools would you choose ? How would you set them up ?... Any suggestions to ease my life ( other than "change to a job closer to home" ) and make this commuting a more productive time ?
Gulp was devoured!
If you get this message when you run gulp,
you have installed devour
which also provides a gulp executable that wraps Gulp and prints this message.
I was having problems building some assets for a project, and eventually discovered this after a lot of hair-tearing trying to figure out why nothing was building. Hopefully the search engines will pick up on this and give more useful results to the next person who has this problem.
Ethernet Aglets
...are technically known as 8P8C modular connectors. It took five of us to figure this out—everyone knew exactly what I was talking about, and nobody could think of the actual name for the things.
How to install NodeJS on Debian/Ubuntu systems using Ansible
Since I've had to figure out how to do this twice now,
and the NodeSource instructions make this more confusing than it ought to be.
Make sure you replace node_6.x with the appropriate version from the
installation instructions
and xenial with the results of lsb_release -s -c.
- name: NodeSource package key
apt_key:
state: present
url: https://deb.nodesource.com/gpgkey/nodesource.gpg.key
- name: NodeSource repository
apt_repository:
repo: 'deb https://deb.nodesource.com/node_6.x xenial main'
- name: Install NodeJS
apt:
state: present
name: nodejs
How to split a git repository and follow directory renames
This is a mirror of my answer to this StackOverflow question.
I had a very large repository from which I needed to extract a single folder; even --index-filter was predicted to take 8 hours to finish. Here's what I did instead.
Rendering a 3D shape with Python
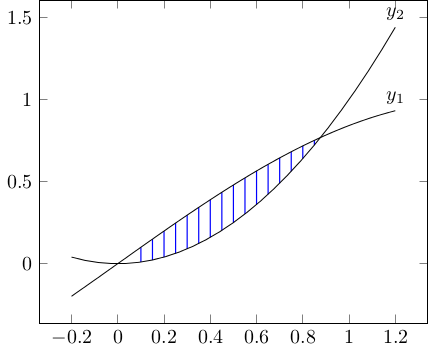
A friend wanted to 3D-print a shape to demonstrate using calculus to find the volume of solids of known cross-section. The shape he wanted was a graph of $sin(x)$ vs $x^2$, where each vertical slice of the intersection was a square. Here's the graph, with $y_1 = sin(x)$ and $y_2 = x^2$. The blue lines show the edge of each square. He couldn't figure out how to do this in a CAD program (I'm not even sure if it's possible), so he asked me if I could write some code to render it.
A Mad Scientist's Guide to Finite State Machines
This was my presentation for the 2015 BarCamp Rochester. Unfortunately I don't have any notes for the presentation, as I did it more or less at the last minute and made up most of what I said on the fly.
Unbound classpath variable: 'wpilib'
Our team runs into this every year, and every year I forget how to fix it:

I decided that this is the year I'll write it down. (Probably now that I've documented it they'll fix it next year.)
Little did Microsoft know...

I found this image on the back of a Microsoft booklet from 1991 called Microsoft products for the Macintosh. This same book contains other gems such as:
My success at breeding captive animals can mean the difference between their survival or extinction. That's why I use Microsoft Mail.
Grant Hutchinson noted:
Keep in mind that in this particular situation, the transaction would be based on the unit values present in the 1991 herring market. The same transaction today would need to have the equivalent herring value calculated at the current rate of exchange.
Use Visual Studio web.config transform for debugging
I have a Visual Studio project which is under version control
and is developed by several people,
all of whom need to have different database and logfile settings during development.
Visual Studio has built-in support for
Config Transforms
for web.config files; all you need to do is
right-click the web.config file in the solution explorer
and click 'Add Config Transforms'.
However, these transforms are applied only when publishing the project,
not when debugging it using Visual Studio.
The solution to this is to implement the config transforms manually with a pre-build task and leave the debug transform out of version control, so each developer can have their own copy.
FRC 2015 Control System Notes
These are notes I took while watching the FRC Behind the Lines episode "2015 Control System Beta Teams" (https://www.youtube.com/watch?v=uUYlS2Vkyuo) They are organized into broad categories, but are otherwise not cleaned up.
Compiling SleepyHead on Ubuntu Trusty
I wanted to install SleepyHead on my new computer (running Ubuntu 14.04 Trusty), but there's no package in the Ubuntu repositories. SleepyHead has instructions for building from source on their wiki, but they don't tell you which packages you need, which is the difficult bit of the process. After some trial and error, I arrived at the following instructions, which worked for me and which I believe to be accurate.
Apache, mod_ldap, and 500 errors
I just finished setting up an Apache server with LDAP authentication. I got everything set up and restarted Apache, but when I loaded a page it blew up with an Apache 500 Internal Server Error. No problem, I thought, I'll just check the logs. Absolutely nothing was being logged. After a lot of searching the Internet, trying things out, and hair-tearing, I eventually discovered that this is a known bug in mod_authz_ldap (#50630).
If your LDAP server is using self-signed certificates, the LDAP module silently fails without logging an error anywhere. To see if this is your issue, try adding the following line to your Apache configuration (remember to restart Apache afterward!):
LDAPVerifyServerCert Off
This will prevent the error from occurring, but also is less secure (someone could pretend to be the LDAP server
and Apache would never know). If this is a concern, set
LDAPTrustedGlobalCert
to your LDAP server's CA certificate.
Rendering HTML5 Video with Handbrake
For my video server project, I needed to be able to show HTML5 videos in a wide variety of browsers. I also didn't want to have to keep multiple copies of the video in different formats (there were a lot of videos, and space constraints). The closest I could get was using MediaElement.js, which provides a Flash player fallback. You should be able to put an MP4 encoded with the [h.264] video codec on your page, and have it work anywhere. It turns out it's not that easy. (iPads, for instance, need a specific sound codec as well.)
After a lot of research, I came up with the following settings for HandBrake, which will create a video that works (in combination with MediaElement.js) on most if not all browsers, looks good, and has a small size. I've tested it on Windows using Firefox, Google Chrome, and Internet Explorer, on Linux using Firefox, and on the iPad using Safari. If you don't want to enter all of these settings manually, you can download a handbrake presets file instead.
Multinomial Probability Mass Function in TI-BASIC
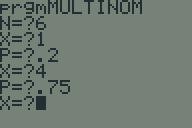
Another TI-BASIC challenge proposed to me by the same person who asked me last time was to calculate the probability mass function of a multinomial distribution. The formula is:
Calculating the mode of a list in TI-BASIC
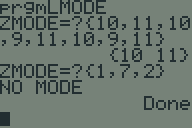
Recently, someone challenged me to write a program to find the mode (or modes) of a list in TI-BASIC. I picked up my TI-83+ and whipped this program up in about half an hour. Somebody else asked me for a copy, so I figured I'd post it on my website.